
SQL in Hex

The SQL controls in Hex are powerful and flexible, but the UI is subtle, so we’re going to unpack how the SQL cell works.
We’re going to address 3 areas:
Return types — this refers to how query results are coming back to Hex. The result sets can be stored in-memory or they can stay in the database/warehouse.
Data connection SQL vs Dataframe SQL — this refers to whether Hex is sending a query to your database/warehouse or whether Hex is querying an in-memory dataframe.
chained SQL — Hex stores the results of SQL queries as variables. These variables can be referenced in subsequent SQL cells. This concept in Hex is called chained SQL. It lets you break down complex queries into smaller steps (which can make your analysis easier to understand).
Return types determine in-memory vs in-warehouse result set
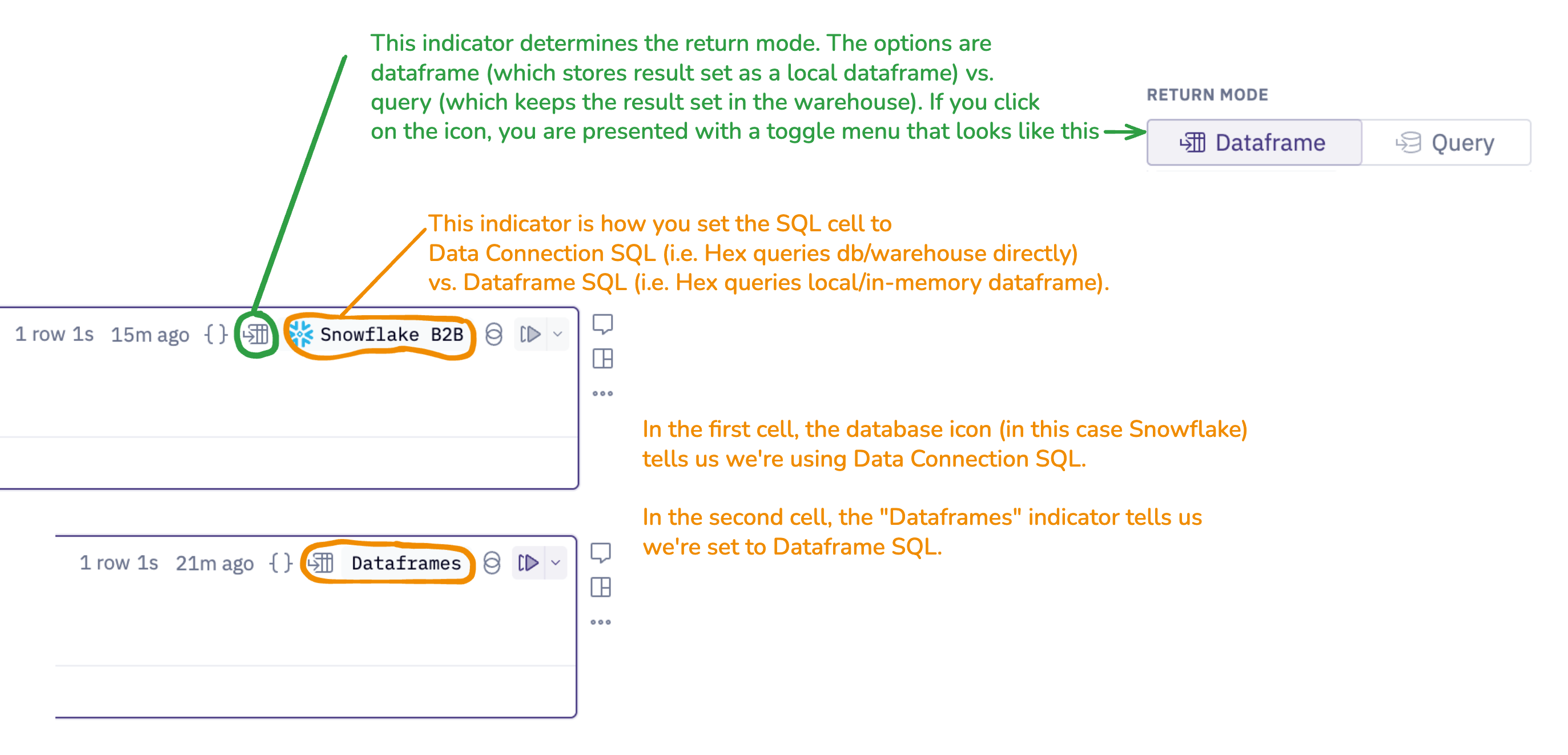
When you make a SQL cell in your Hex project, there’s a “Return Mode” indicator at top right where you can choose “Dataframe” or “Query”. This specifies whether the result set from the database should be stored locally in Hex or should stay in the database.
This is how you select your return type:
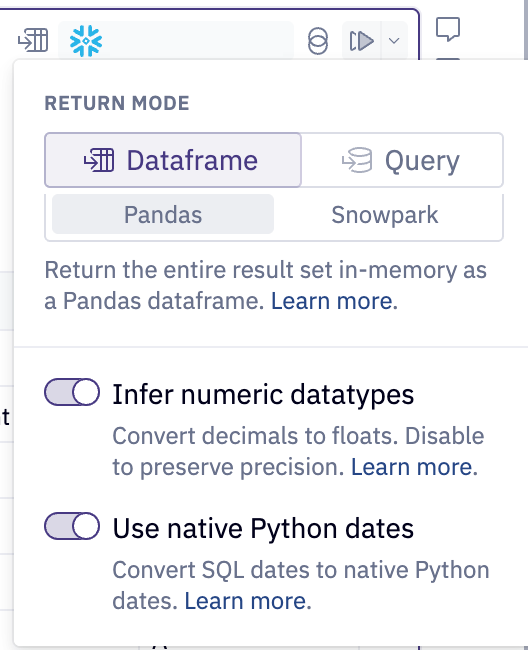
Dataframe mode (🦆): in-memory
Dataframe mode refers to when the database returns the result set, and it is stored locally in Hex (as a DuckDB dataframe).
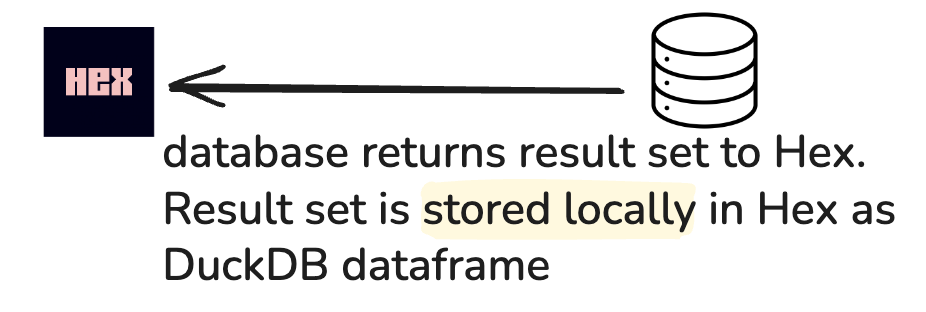
Implication: Since this brings the data into memory, subsequent queries against the dataframe won’t hit the database, potentially saving on query costs. Python cells and no-code cells can also reference the dataframe.
Query mode (❄️): in-warehouse
Query mode refers to when the database returns the result set, but the result set is not stored in Hex — instead it remains in the database/warehouse.
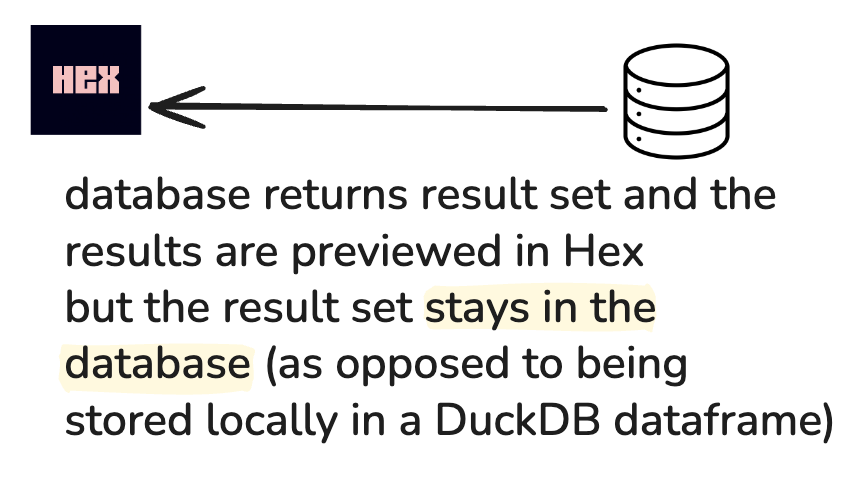
Implication: The data stays in the warehouse, which may be more performant for very large data sets. However is you want to use Python, the query mode data will be brought into memory1.
We’ve covered Return modes — which told us how/where the query results are being stored. Now' let’s talk about the difference between Hex querying the database/warehouse vs local dataframes (DuckDB).
Data connection SQL vs Dataframe SQL
Data connection SQL vs Dataframe SQL refers to whether Hex’s SQL query is hitting the database directly or if it’s hitting a local DuckDB dataframe. The syntax for Data Connection SQL will be dependent on the database you’re querying (e.g. Snowflake, BigQuery, Databricks, etc.). The syntax for Dataframe SQL will be DuckDB’s syntax (which is similar to Postgres).
In the top right corner of your SQL cells, you can set the cell to DataFrame SQL or Data Connection SQL.
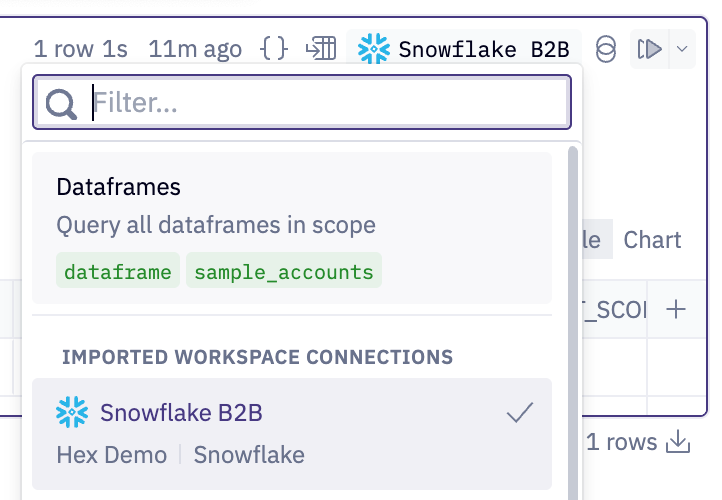
Data connection SQL
Data connection SQL refers to any query that goes directly against the database/warehouse, regardless of whether the result set is stored in Hex or stays in the database.
The initial SQL query in a Hex project will always go directly against the database (unless you’re querying a CSV).
Dataframe SQL
Dataframe SQL means Hex is sending a query to the in-memory Duckdb dataframe. As a result, the return mode will always be dataframe, since there is no interaction with a warehouse in this scenario.
Where things get powerful
Hex lets you chain together SQL queries — this lets you break down complex queries into smaller steps with intermediate results along the way.
Where things can get confusing
It’s important to know whether your query is hitting the warehouse or local dataframe — especially if it’s an expensive query.
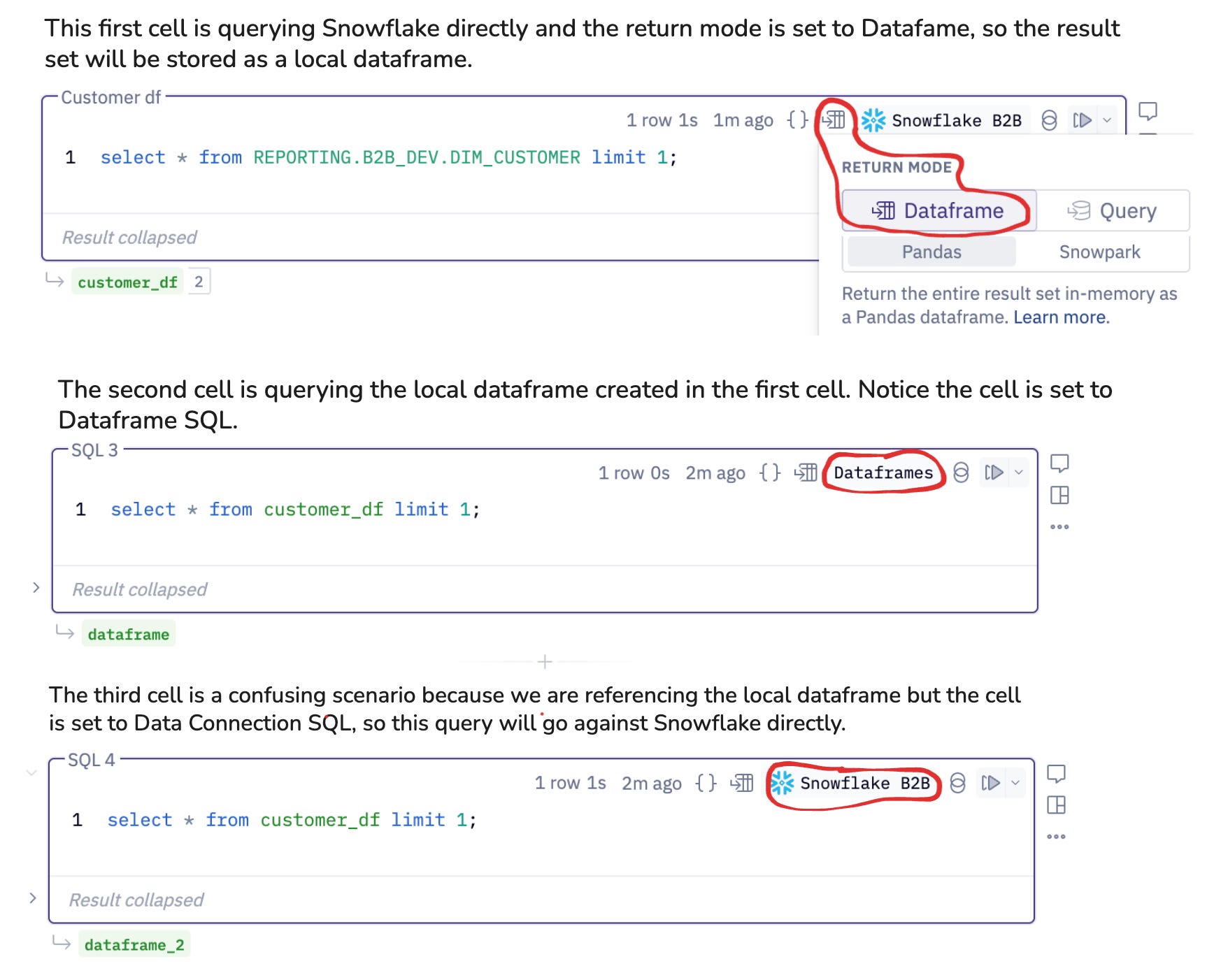
Chaining SQL allows you to go back and forth between writing SQL against the in-memory dataframe (Dataframe SQL) and the warehouse (Data Connection SQL). Below is an example of workflow where it looks like the third cell should be querying a local dataframe, but it is actually sending a query directly to Snowflake.
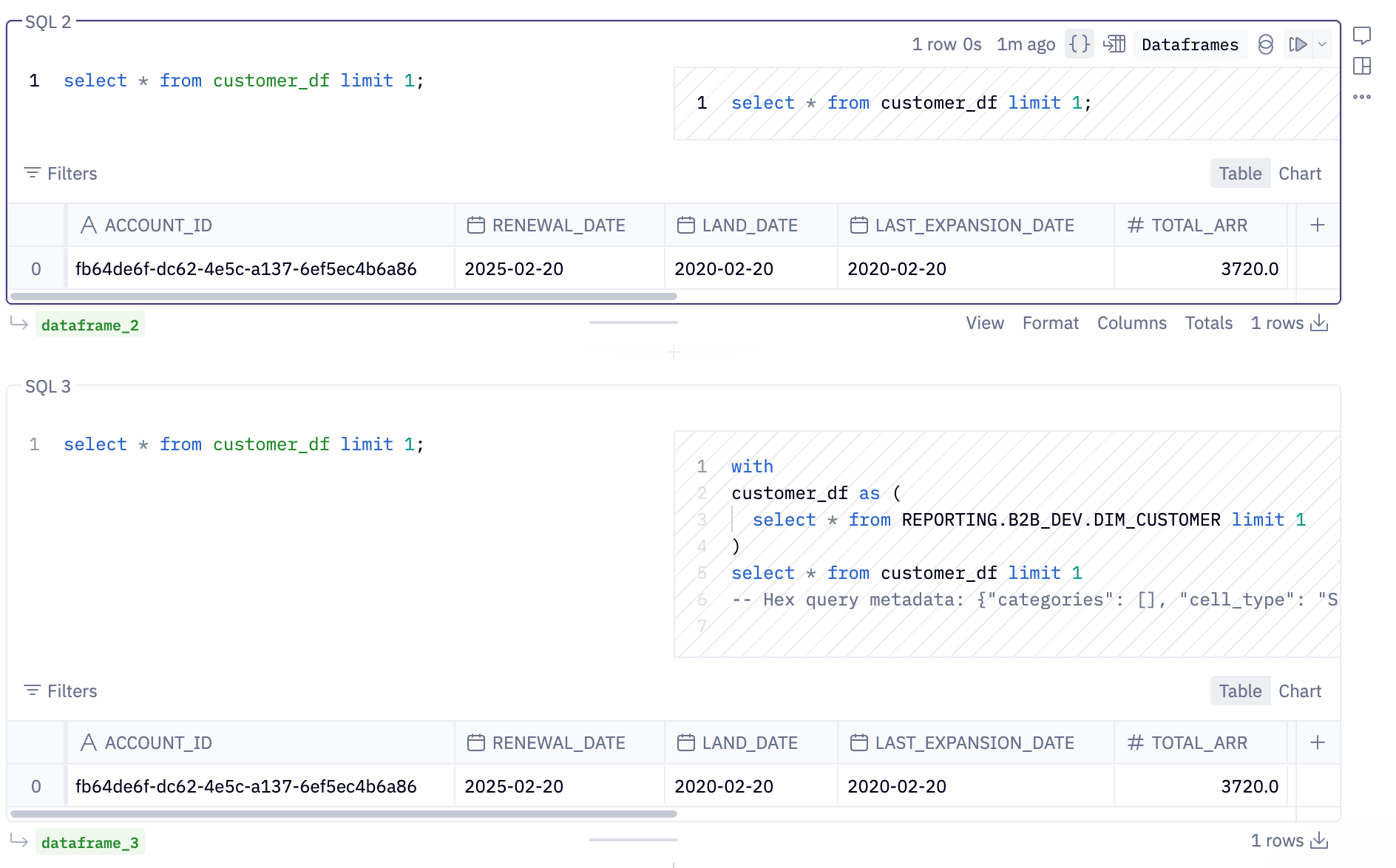
In order to confirm what the SQL cells are doing, you can always view the compiled SQL. Clicking the { } indicator will reveal compiled SQL:
There are 3 main scenario
In summary, there are 2 main controls within a SQL cell which yield 3 main scenarios.
The controls are:
Connection SQL vs Dataframe SQL
Return mode: Dataframe vs Query Mode
And the scenarios are:
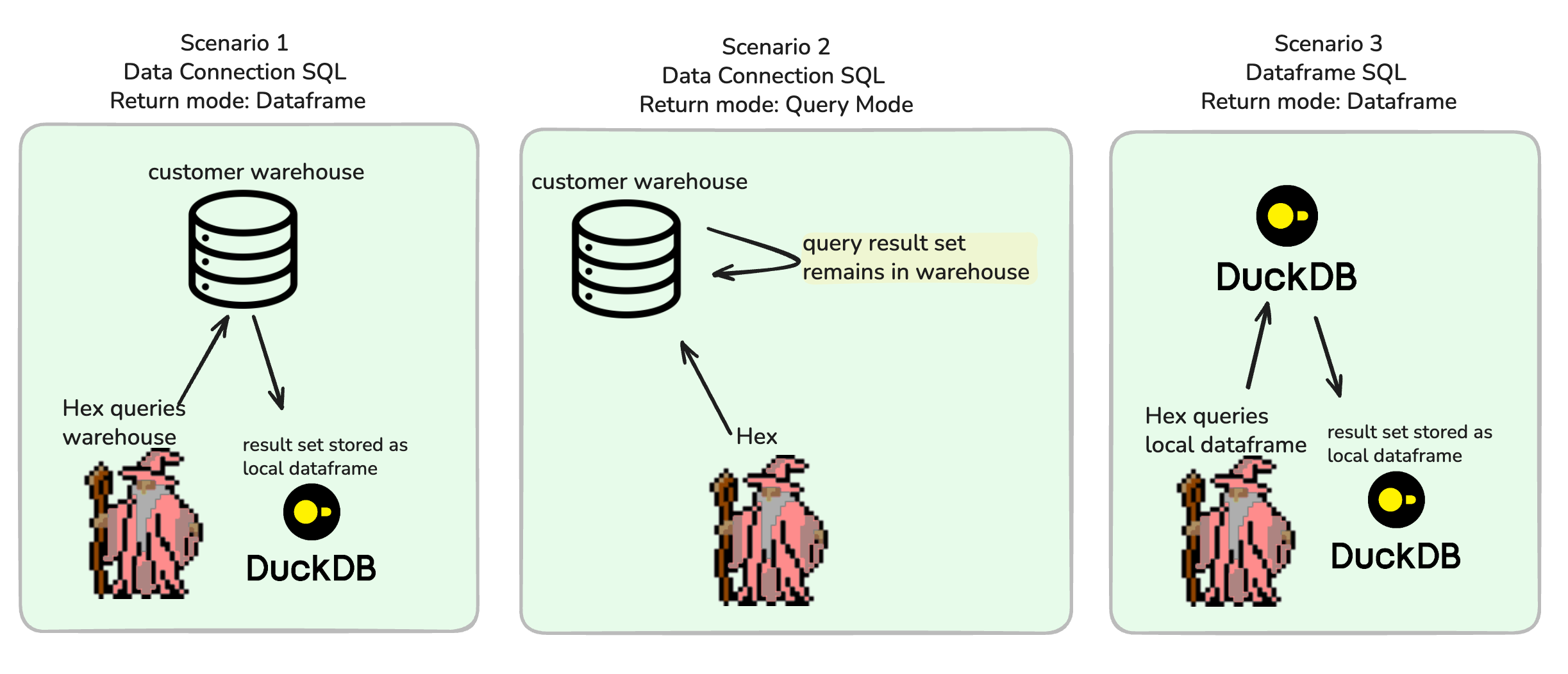
This diagram doesn’t explicitly cover cross-database-joins, but those would fall under Scenario 3.
You can join across dataframes, but you cannot directly join across dataframes and database tables. If you want to join a dataframe and a db table, you'll need to first run a data connection SQL query to get that table as a dataframe in your project. Once everything is a dataframe, you can join the two together.
With the exception of Snowpark users — you can write Python code against a Snowpark dataframe and have the processing take place in Snowflake.